Over the years, I’ve grown quite comfortable with Python, mostly during my work as a financial risk manager. It’s a language I know well and have relied on for building data processing pipelines, risk measurement libraries, but also for automating some of the boring stuff, like scraping the web or assembling PDF from e-books for offline studying.
But as time has gone on, I’ve found myself increasingly drawn to functional languages, both for their elegance and for the different mindset they encourage when designing software. It is during this exploration that I have discovered the languages running on the BEAM (the Erlang virtual machine), such as Gleam and Elixir.
On top of the functional philosophy which aims to eliminate or at the very least contain side-effects, as well as the wonderful pipe operator, the BEAM languages boast an incredibly compelling concurrency model thanks to their runtime, where spawning super lightweight processes to run code asynchronously is as simple as writing:
# This code runs in a process
x = 10
spawn(fn -> x ** 2 end) # This code runs in a separate process!
Elixir also brings a powerful macro system that transforms the Elixir AST at
compile time, which can make writing code much more compact. For example, the router inside of a web server
could be written as such (see Plug.Router).
get "/hello" do
send_resp(conn, 200, "world")
end
match _ do
send_resp(conn, 404, "oops")
end
But my work is in financial risk management, an area that requires of a programming language to provide data exploration capabilities, numerical computing packages with decent performance, as well as good tooling.
Can Elixir tick those boxes? To which extent would I still need Python to do that work?
In this post, I take a closer look at Elixir’s ecosystem with those questions in mind, to determine whether Elixir can realistically replace Python in my workflows, and to start to define the toolbox I will be using going forward.
Numerical computing
In the last few years, the Elixir team has made a large effort to bridge a gap identified in BEAM languages: the lack of libraries and tooling for numerical computing. The fault tolerance, high concurrency, and distribution capabilities of the BEAM makes it a great target for implementing machine learning algorithm, as long as the linear algebra toolbox is there.
This is why Nx ("Numerical Elixir") was born.
Nx's main contribution is the definition of tensors in Elixir (i.e. multi-dimensional arrays), as well as operations on these tensors. For example, defining a vector and computing the differences between neighbors can be written:
Nx.tensor([1, 6, 7, 4, 3, 2, 8, 3])
|> Nx.diff()
|> IO.inspect()
# #Nx.Tensor<
# s32[7]
# [5, 1, -3, -1, -1, 6, -5]
# >
This also includes the ability to generate random tensors based on pre-defined distributions:
{arr, _new_key} =
Nx.Random.key(1)
|> Nx.Random.normal(0, 1, shape: {500})
IO.inspect(arr)
# #Nx.Tensor<
# f32[500]
# [-1.9280794858932495, -0.8847223520278931, 2.186722993850708, ...]
# >
If you're wondering what "keys" are in this context, think of them as the state of the pseudo-random number generator ("PRNG" for short). We start by generating a key using an integer seed (here, 1), and generating a vector will also generate a new key. Should we wish to generate a new vector, backed by the same initial seed, we would use that new key to do so.
For now, Nx seems like a replacement for Python's numpy library. But, it also provides additional functionality. For instance, Nx allows us to turn our computations into graphs that can be optimized and compiled to run on accelerators (GPUs or TPUs), making it more akin to a library like pytorch.
For example, the substract function (an admittedly contrived example) in the following code uses the defn macro (as opposed to def, which is used for normal Elixir functions) provided by Nx.Defn to make it operate on tensors, and allows us to compile it for efficient use.
defmodule TensorMath do
import Nx.Defn
defn subtract(a, b) do
a - b
end
end
Finally, Nx also provides auto-differentiation for functions defined using
defn, which is useful for calibrating models. Here is a trivial example
using a quadratic polynomial.
defmodule Quadratic do
import Nx.Defn
defn f(x, a, b, c) do
a * x ** 2 + b * x + c
end
defn gradient(x, a, b, c) do
grad(fn x -> f(x, a, b, c) end).(x)
end
end
{a, b, c} = {1, 2, 3}
x = 0
Quadratic.gradient(x, a, b, c)
|> Nx.to_number()
|> IO.inspect()
# 2.0
IO.inspect(2 * a * x + b)
# 2
Based on these features, I'd say Nx is very capable of powering our calculation
engines!
The Python escape hatch
The Nx team realized that for Elixir to gain adoption for Machine Learning applications, it had to have access to Python libraries in some way, so as to avoid having to reimplement all of those existing algorithms by hand in Elixir, which would prove prohibitively expensive as a preliminary requirement.
Historically, there has been three main ways of calling Python within Elixir:
- Call the
pythoninterpreter viaSystem.cmd. This approach is simple, but not ideal when we need to pass data between Python and Elixir. - Maintain a separate Python service. This approach also has drawbacks, as it would require the set up of a deployment pipeline as well as an API layer.
- Using a Port, which takes care of inter-process communication, using message passing.
This year, a fourth option has been implemented: Pythonx, mostly for use within Livebook (more on that later).
Pythonx is a library that allows us to initialize a Python interpreter in the same OS process as the BEAM VM (which is different from the other three options), using Native Implemented Functions (or "NIFs" for short) to communicate with Elixir. This is a compelling approach that seems to have great ergonomics. For example, it allows us to directly
supply a pyproject.toml specification and run uv from within our Elixir code
to initialize the interpreter.
Pythonx.uv_init("""
[project]
name = "project"
version = "0.0.0"
requires-python = "==3.13.*"
dependencies = [
"scipy==1.15.3"
]
""")
# Using CPython 3.13.1
# Creating virtual environment at: .venv
# Resolved 3 packages in 342ms
# Installed 2 packages in 47ms
# + numpy==2.3.0
# + scipy==1.15.3
# :ok
However, because of the Global Interpreter Lock ("GIL"), we are (for now) unfortunately limited to running a single Pythonx interpreter per BEAM instance, which means we cannot easily benefit from the concurrency model that Elixir provides.
For use in a production server where concurrency is likely to be important, we would consider the following patterns:
- Using the Port of
System.cmdapproaches defined above, using a pool of worker processes. - Call
PythonxusingFLAME, although the overhead might be a bit too much.
Finally, using NIFs can be a bit dangerous, as there is often no guarantee that an unhandled exception wouldn't crash the VM process, which removes ruins any chance at fault tolerance, a big selling point of the BEAM.
For testing and building models outside of a production environment however, Pythonx is a great option, and will see a great deal of use from me.
Data exploration
In my mind, exploring data requires the following elements to be available to us:
- Some kind of cell-based editor, or at the very least a shell with command history and variable explorer.
- A construct and library for working with tabular data (e.g. dataframes).
- A library for constructing charts.
In Python, these boxes are all ticked, as any Python user working with data
would be very familiar with tools like Jupyter notebooks, pandas or polars,
and matplotlib.
| Aspect | Tools | Python? | Elixir? |
|---|---|---|---|
| Editor | Jupyter notebooks, JupyterLab, Spyder | ✅ | ❓ |
| Dataframe library | pandas, polars |
✅ | ❓ |
| Graphs library | matplotlib, seaborn, plotly |
✅ | ❓ |
Livebook - A cell-based code editor for Elixir, and much more
Livebook is a web-based interactive notebook application built for Elixir. Much like Jupyter notebooks in the Python ecosystem, Livebook enables us to combine code, text, and visualizations in a single, executable document.
However, Livebook is much more than a re-implementation of Jupyter notebooks, as it has been built to take full advantage of the BEAM and Elixir. For example, you can use a Livebook to introspect a live, running system (e.g. a Phoenix web application) using the power of Distributed Elixir. In addition, Livebook is aware of variables used in each cells and will make sure to re-compute any stale cells those variables are involved in, thus avoiding the most stale data issue that is ubiquitous to any Jupyter-based workflow.
For a mind-blowing demo showing off what Livebook has to offer, I recommend the following talk by Elixir's creator, José Valim:
That's our first box ticked! ✅
Explorer - An elegant dataframe library
Working with Nx tensors is great, but in many situations, we will not need to work in multi-dimensional space, and instead, we will have tabular data, i.e. a set of labelled, 1-dimensional arrays. In Python, the excellent pandas allows us to deal with that type of data quite easily, providing convenience functions and tools right at our fingertips.
In Elixir, we have Explorer, a library that wears its influence by dplyr on its sleeve, and boasts high speeds by leveraging on a polars backend.
For users of polars, the API will take a little bit to get used to as it is a little bit different, but it does retain the elegance we know and love. The Explorer query engine is a powerful tool that allows us to manipulate data using very compact syntax, and plays relatively well with Nx numerical definitions, should we need to define our own tensor functions.
We show off some of these functionalities in the example below, where we compute the result of the Kupiec POF test on a rolling window basis based on randomly simulated VaR overshootings.
require Explorer.DataFrame, as: DF
require Explorer.Series, as: DS
n = 5000
var_cf = 0.99
th_os = 1 - var_cf
window = 250
test_cf = 0.05
{arr, _new_key} =
Nx.Random.key(1)
|> Nx.Random.uniform(shape: {n})
# Simulated dataset
DF.new(%{
# An incrementing row index
idx: Nx.iota({n}) |> DS.from_tensor(),
rand: DS.from_tensor(arr)
})
# Define overshootings based on the outcome of random uniform sampling
|> DF.mutate(
os:
cond do
rand < ^th_os -> 1
true -> 0
end
)
# Aggregate over 250-day windows
|> DF.mutate(n_os: window_sum(os, ^window))
# Remove while the first window is being built
|> DF.slice((window - 1)..-1//1)
|> DF.mutate(
th_os: ^th_os,
n_obs: ^window,
f_os: n_os / ^window
)
# Compute the Kupiec likelihood ratio
|> DF.mutate(
num: th_os ** n_os * (1 - th_os) ** (n_obs - n_os),
denom: f_os ** n_os * (1 - f_os) ** (n_obs - n_os)
)
|> DF.mutate(kupiec_lr: -2 * log(num / denom))
# Compute the p-value for each value of the likelihood ratio
|> Kernel.then(fn df ->
DF.put(
df,
:p_value,
DS.transform(
df["kupiec_lr"],
fn x -> 1 - Statistics.Distributions.Chisq.cdf(1).(x) end
)
)
end)
# Only retain important information
|> DF.filter(p_value < ^test_cf)
|> DF.select([:idx, :kupiec_lr, :p_value])
|> DF.print()
# +--------------------------------------------------+
# | Explorer DataFrame: [rows: 555, columns: 3] |
# +-------+-------------------+----------------------+
# | idx | kupiec_lr | p_value |
# | <s32> | <f64> | <f64> |
# +=======+===================+======================+
# | 2356 | 5.025167926750725 | 0.024981503053449705 |
# +-------+-------------------+----------------------+
# | 2357 | 5.025167926750725 | 0.024981503053449705 |
# +-------+-------------------+----------------------+
# | 2358 | 5.025167926750725 | 0.024981503053449705 |
# +-------+-------------------+----------------------+
# | 2359 | 5.025167926750725 | 0.024981503053449705 |
# +-------+-------------------+----------------------+
# | 2360 | 5.025167926750725 | 0.024981503053449705 |
# +-------+-------------------+----------------------+
This is our need for ergonomic tabular data handling met! ✅
Charting in Elixir
There are many ways to build charts in Elixir, but they often require us to bind to an external engine, either via a NIF or Javascript.
For example, nothing prevents us to take a dataset, turn it into JSON, and then pipe it into a graph built with tools like ECharts or D3.
For something a little bit more ergonomic, we can use the Livebook-maintained vega_lite library, which provides convenient functions for building up VegaLite graph specifications, and then use vega_lite_convert, which binds to a Rust conversion library for VegaLite.
Let's build a chart for out p-values of our Kupiec test defined above.
alias VegaLite, as: Vl
df = ...
# Create a new chart
Vl.new(
width: 800,
height: 400,
title: "Kupiec POF p-values over time"
)
|> Vl.config(
view: [fill: :white],
padding: 20
)
# Bind data to the chart
|> Vl.data_from_values(
idx: df["idx"] |> DS.to_list(),
p_value: df["p_value"] |> DS.to_list()
)
|> Vl.layers([
# Our first layer, the actual data
Vl.new()
|> Vl.mark(:line)
|> Vl.encode_field(:x, "idx", type: :quantitative, axis: [title: "Time step"])
|> Vl.encode_field(:y, "p_value", type: :quantitative, axis: [format: ".0%", title: "P-value"]),
# A horizontal line that shows the p-value threshold
Vl.new()
|> Vl.mark(:rule, color: "red", stroke_dash: [4, 4])
|> Vl.encode(:y, datum: 0.05, type: :quantitative)
])
# Conversion to an image file
|> VegaLite.Convert.save!("vegalite-chart.png", ppi: 300)
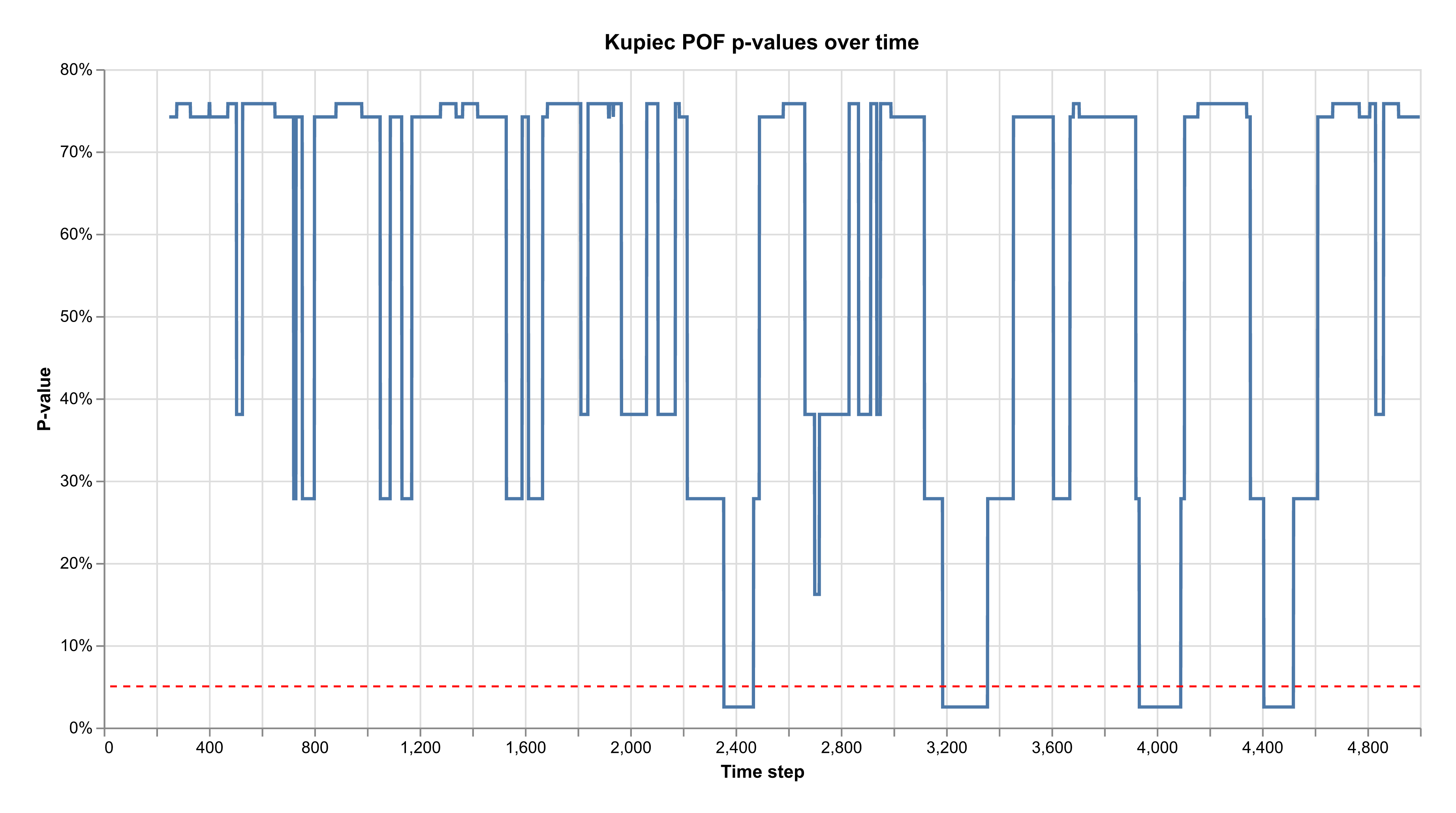
The documentation for VegaLite is excellent, and the Elixir package is pretty transparent, making it quite easy to build the charts we want. I have also found that LLMs do a pretty good job at providing the required API when I've forgotten how to do something specific.
Charting is quite easy in Elixir, and we can always use a Javascript if we need something highly interactive (just like we do it in Python)! ✅
Conclusion
Elixir has one of the strongest community surrounding a programming language I have ever seen. While it is a niche language, with only 2.1% of the 2024 StackOverflow reporting having done significant work with it over the year, it is one of that developers enjoy a whole lot, with 76% of the same respondents reporting that they admire the language.
The elegance of the language coupled with the concurrency model provided by the BEAM makes it a compelling language for writing all kinds of applications, mostly on the backend side of things.
Since it seems that it can mostly replace Python for my kind of work, and has a decent interoperability story with Python, it is definitely a technology I will keep learning and invest into.
Stay tuned for more Elixir content!